Understanding and Addressing Concept Drift in Website Fingerprinting
Authors: Roie David , Anatoly Shusterman , Yossi Oren
Appeared in: Elsevier Computer Networks Journal, to appear
Abstract
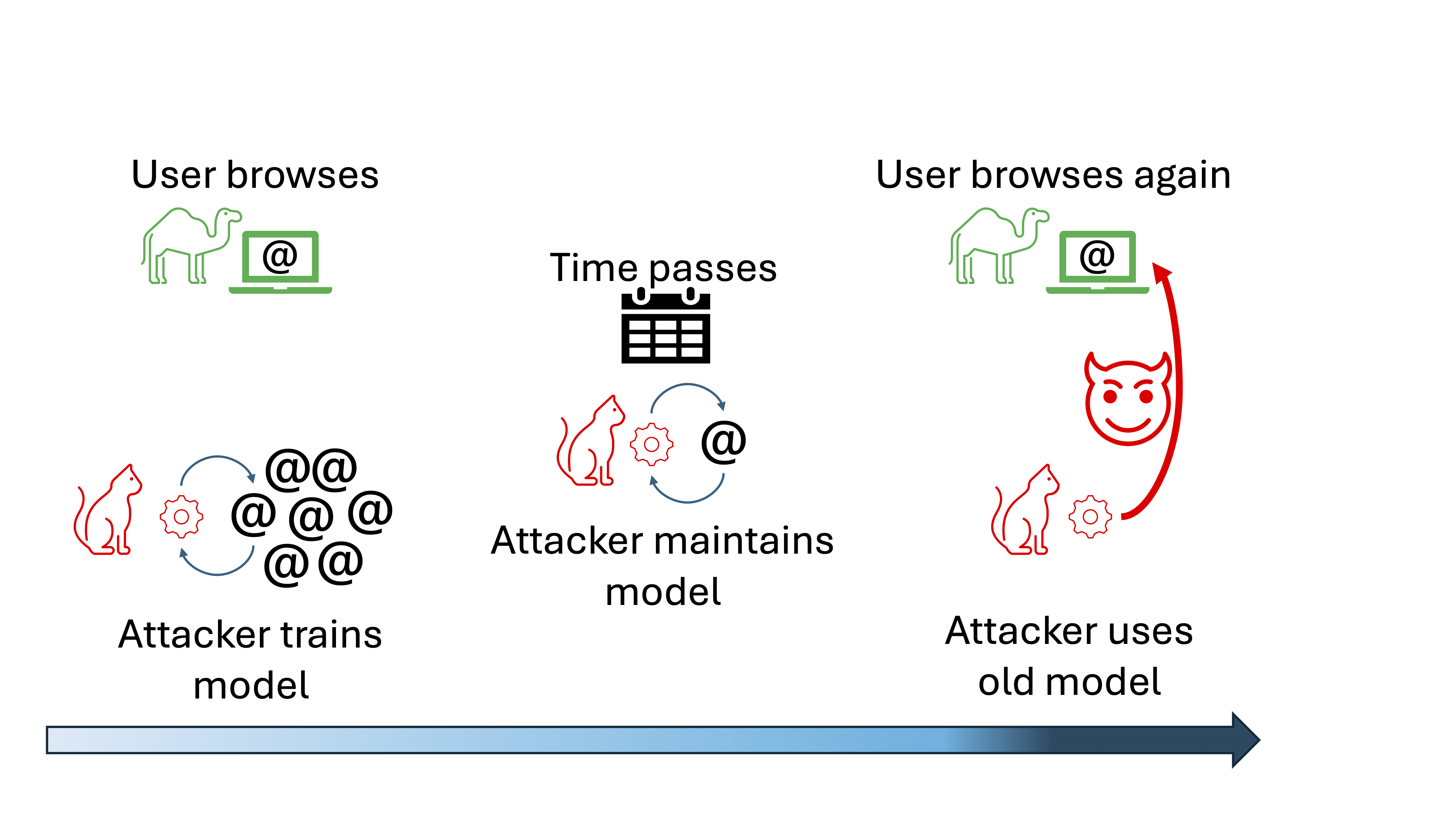
Website fingerprinting attacks let attackers determine which websites a user visits, posing a significant risk to online privacy. Website fingerprinting attacks have been demonstrated both in the network-based setting, where the adversary is able to observe the network traffic between the user and the secure network, and in the cache-based setting, where the adversary injects malicious JavaScript code into the user’s browser and observes memory activity. In both of these settings, previous research has demonstrated that state-of-the-art website fingerprinting attacks can succeed even in highly-constrained environments, for example when attacking the privacy-enhanced Tor browser. One known limitation of website fingerprinting attacks, however, is their sensitivity to concept drift — as the time difference between the training period and the actual attack grows, the accuracy of the model used in the fingerprinting attack degrades due to changes in webpage content, network conditions, and the software implementation of the browser. This phenomenon is a known challenge in website fingerprinting.
This study provides a quantitative analysis of the effect on website fingerprinting attacks of concept drift in both the network-based and cache-based settings, based on a website fingerprinting trace dataset collected over a period of several months. It examines the effect on accuracy of changes both to the browser version and to the website content. It then investigates multiple approaches for addressing concept drift, assuming the attacker can add a limited amount of fresh data to his training dataset.
Our evaluation shows that using advanced machine learning techniques can significantly reduce the effect of concept drift on website fingerprinting attacks, and that, specifically, an incremental learning approach nearly maintains the model’s accuracy over time, while requiring only 2% of the data needed for full retraining. This finding demonstrates the practicality of long-term website fingerprinting attacks in the real world.
 Draft version
Draft version Artifact Repository
Artifact Repository