Introduction to micro-architectural attacks
- Introduction to micro-architectural attacks
Clementine Maurice, CNRS, IRISA
April 30, 2019 — Ben Gurion University, Israel
Background & Primitives
Micro-architectural side-channel attacks refer to a side-channel attack that exploit information leakage from the hardware infrastructure itself. The attacks can be found in a large scope of devices - servers, workstations, laptops, smart-phones, etc.
Normally, we assume a safe software infrastructure, meaning that no software bugs, such as buffer overflow, is present. Nevertheless, such assumption does not imply safe execution, due to the fact that the information leaks because of the implementation, which is often driven by complex optimizations and design. Such leakages are not considered as ’mistakes’ or ’bugs’, but rather a trade-off decision between optimizing some aspects of the execution and potential information leakage.
Potential outcomes of such attacks as described can be crypto primitives, which is common with other side-channel attacks, but also other sensitive information such as keystrokes and mouse movements.
In terms of sources of leakage, we saw in previous chapters sources such as power consumption or electromagnetic leaks. However it’s harder for an attacker to come across such sources because they require physical proximity and access to the device, which are more typical to embedded devices. In this case the requirement is that the attacker will have somewhat remote access to the device, meaning that the attacker can run code on the hardware infrastructure of the machine. Such scenarios can be found in cloud providers renting computational resources to a costumer, Java-Script code running in a browser and others.
Example: Cache attack on RSA Square-and-Multiply Exponentiation
Consider the binary exponentiation algorithm presented in Algorithm [algo:SaM]. Notice that the execution flow of the algorithm relies heavily on the value of the bit ei of the private key. Now consider a scenario in which an attacker has information on the changes regarding the buffer holding the multiplier b. Such information can be considered as a query to the buffer and receiving as a result the latency of the query. If the buffer is in use, the query will be longer than if the buffer is unused.
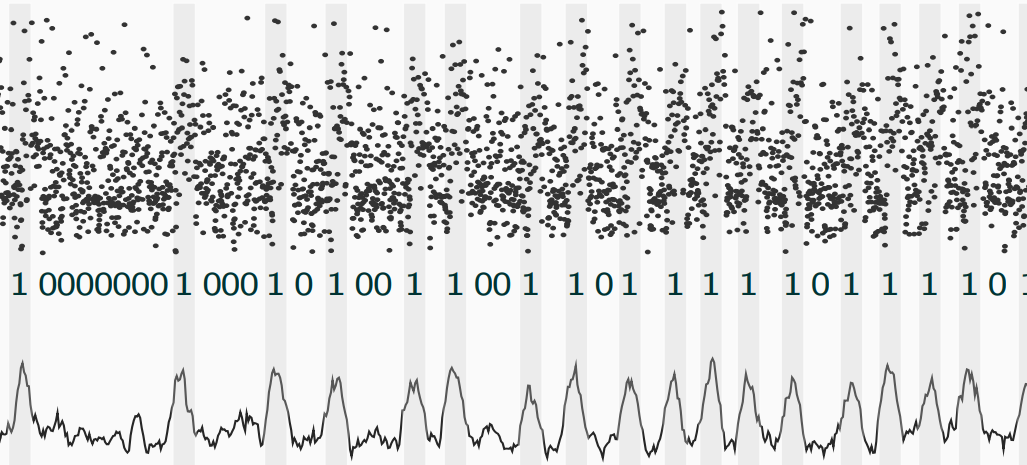
In , the graph of the querying result, the actual bits of the exponent can be clearly detected.
Attack Model
We assume that the attacker has no physical access to the device. Moreover, the attacker can only execute unprivileged code on the same machine as the victim. Such scenarios in which this happens can be found, for example, when the victim installs some malicious program on his machine/smartphone. Other examples can be found in cloud computing where an attacker has a virtual machine on the same physical machine as the victim, or in a web environment in which the attacker runs unprivileged JavaScript code.
In the scope of this chapter we will focus on shared hardware in the form of data/instructions that are stored in the cache. While other shared hardware components can also include the DRAM and the memory bus (memory shared hardware) or the branch prediction unit and the arithmetic logic unit (CPU shared hardware), they are not in the scope of this chapter.
Today’s CPU Complexity
From 2012 Intel has released a new family of microprocessors every year. Each comes with its own new microarchitectural schemes with new characteristics. To gain performance upgrade in each new installment (on average 5% increase in performance depending on the feature), minor optimizations, such as caches and branch prediction units are added. Such optimizations are the main reason that side-channel information leakage exists. Unfortunately, these optimizations often come with no documentation since this is Intel intellectual property. Lack of documentation can make it harder for an attacker to perform said side-channel attacks.
To emphasize today’s CPU complexity, it is said that “Intel x86 documentation has more pages than the 6502 has transistors” , with 6502 being a reference to a 8-bit microprocessor, used in Apple II, Commodore 64, Atari 800 and more. It had, in the year 1975, roughly 3510 transistors, while the Intel Software Developer’s Manuals is 4844 pages (may. 2018). In a more advance microprocessor, such as the 22-core Intel Xeon Broadwell-E5, more than 7 billion transistors can be found.
Background on Caches
When designing a cache side-channel attack, a proper understanding of how caches work, in detail, is required. First, we need to acknowledge that the requirements for an ’ideal memory’ oppose each other. Such requirements are zero latency, infinite capacity, zero cost and infinite bandwidth. The trade-offs are interconnect: Bigger is Slower - Bigger memory often comes with higher latency, due to the fact that it would take longer to determine the location to retrieve. Faster is Expensive - A reduction in latency often means that a more expensive technology is needed. For example, SRAM is faster than DRAM, which in turn is faster than Disk memory. However, their cost ratio is the other way around. Bandwidth is Expensive - A wider bandwidth needs to come with additional banks, ports, higher frequency or faster technology.
In our need to understand the use of cache, we need to examine the different memory technologies and why they are used in the way they are used. DRAM - Dynamic Random Access Memory is the technology that is often used as the main memory (or RAM), while SRAM - Static Random Access Memory is the technology used in cache memory. The DRAM latency is higher than the SRAM latency, but is cheaper to make. The main difference in cost arises from the fact that DRAM consists only of one transistor and one capacitor per cell, while the SRAM consists of six transistors per cell. These differences also mean that the DRAM is more dense. Finally, the DRAM cell layout and technology requires to periodically refresh each cell.
Since having Both a large and fast, single level of memory is unlikely, CPU’s today are made with multiple levels of storage. The main idea is that progressively bigger and slower storage units are located in higher levels of memory, which are farther from the processor. The motivation for such design is to ensure that most of the data the processor needs is kept in the closer and faster levels.

The memory hierarchy can be seen in , where data can reside in, at a given point in time, in the following storage units - in CPU registers, the different levels of the CPU cache, main memory or disk memory.
Caching Basics
The two main ideas of caching are to exploit temporal and spatial locality. Temporal Locality is the notion that a program tends to reference the same memory location many times within a small window of time (for example, loops). The anticipation of such thinking is that recently accessed data will be accessed again soon. Therefor, a good strategy will be to store recently accessed data in automatically managed fast memory. Spatial Locality is the notion that a program tends to reference a cluster of memory locations at a time (for example, sequential instruction access or array traversal). The anticipation will be that surrounding of some accessed data will be accessed soon. A good strategy will consider storing addresses adjacent to the recently accessed one in an automatically managed fast memory. In detail, we want to logically divide memory into equal size blocks (lines) and fetch to cache the accessed block in its entirety.
Moreover, there are two approaches to the management scheme, manual and automatic. Manual Management means that the programmer manages data movement across levels, which is not scalable for substantial programs. However, it is sometimes used in some embedded systems. Automatic management refer to a scheme in which the hardware itself manages data movement across the different levels in a way that is transparent to the programmer. Meaning that the average programmer does not need to know anything related to the memory hierarchy levels to write a program. On the down side, which begs the question on how to write a fast program if the management is automatic, in addition to what kind of side-channels could arise from such scenario.
The basic unit of storage in the cache is called a block or a line. The main memory is logically divided into cache blocks that map to locations in the cache. And when data is referenced, two outcomes can come of such action - a cache hit or a cache miss. A Cache Hit occurs when a line is referenced and is in the cache. The cached data will be retrieved instead of accessing main memory. A Cache Miss occurs when a line is referenced and is not in the cache. The data will be fetched from main memory, passing through the cache, possibly evict other line to ensure enough storage.
When designing a cache, we are faced with a number of design decisions to handle. Placement - Essentially the location in which we will place or find a block in the cache. Replacement - We need often to remove data from the cache to make room for newer data. Which begs the question of what data to evict. Granularity of Management - The basic units of storage in different levels. Do we store the same amount of blocks across different levels or do we uniformly store the same size of blocks. Write Policy - When a write operation is being made, we need to decide whether to preform the write operation in all levels or pass the write data to a lower level only upon eviction from that level. Instruction/Data - When a program is executing, the instructions that are in need to be executed are required to be fetched from memory as well. The designer needs to decide whether to treat instructions and data memory as two separate types or as the same.
Set-Associative Caches
We will be focusing on a cache design that is often used in today’s CPUs, which is set-associative caches. Which means that the cache will be logically divided into Cache Sets, which will be divided into Cache Ways. Each way will store a cache line worth of data. The division of the memory into different cache sets will be a direct mapping from the memory address. Namely, each address will be associated with a cache set according to a group of bits in the address which will represent the cache set index. The specific way in which the line is fetched will be determine according to the cache replacement policy, since the cache set is expected to be full. An abstraction can be seen in
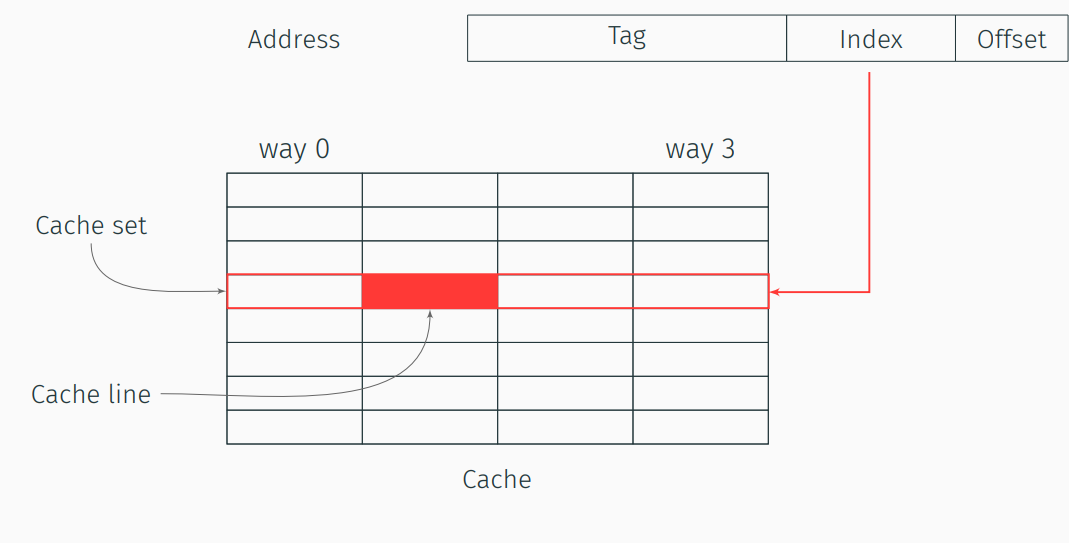
Consider the following example: The cache has 8B cache lines, 16 cache sets each consisting of 2 ways. We can compute the set index of the address (1011111110)b by only looking at bits b3, b4, b5, b6, since we have 16 cache sets (4 bits) and 8 different cache line offset (bits b0, b1, b2). Hence the cache set will be (1111)b. We can also compute the size of the whole cache by multiplying the cache dimensions 8 × 16 × 2 = 256B.
Virtual Addresses or Physical Addresses
Since we need the bits of address to determine its cache set, we are face with a problem due to the fact that programs running are only aware to the virtual addresses while the hardware side is aware to the physical addresses. The translation between virtual addresses and physical addresses is the responsibility of the MMU (Memory Management Unit).
There are four major ways of implementing such cache mapping according to the addresses. VIVT - Virtually-Indexed, virtually-Tagged. Meaning that there is no need to translate the addresses in order to know the mapping of the addresses into the cache, which is faster. On the other hand, such implementation causes aliasing issues as same virtual address maps to several different physical addresses. This aliasing is due to the tag not being unique, and will force a flush action to the entire cache on context switching. VIPT - Virtually-Indexed, Physically-Tagged. Meaning that there will be a need for TLB translation for the tag, but can be looked up in parallel. Such mapping can be quiet fast. Moreover, if the set index bits are derived from the page offset, there is no aliasing, but the cache size is limited to the page size multiply by the number of cache sets. VIPT is used in Intel’s L1 caches, with the default page size being 4K and each cache line is 64B, resulting in no larger than 26 = 64 sets. PIPT - Physically-Indexed, Physically-Tagged. Meaning that the translation between virtual and physical addresses will have to be preformed, taking up time. On the other hand, no aliasing issues occurs and no required limitation on the number of sets is present. Typically used in the larger Intel caches - L2 and L3. PIVT - Physically-Indexed, Virtually-Tagged. Meaning that all the limitations of previous ways apply, and is rarely used in practice.
Replacement Policy
We need to decide on a policy according to which a cache line will be evicted in order to make room for incoming data. Many replacement policies exist, namely FIFO (first in, first out), LRU (least recently used), LFU (least frequently used), random, a hybrid and more.
Intel commonly applies a LRU policy or a pseudo-LRU policy (since pure LRU is complex to implement). Which determines that the oldest cache line to be referenced will be evicted, As if each cache line is attached with a time-stamp that is updated on access. An example can be thought of by having n way cache set and n + 1 different lines of memory that are mapped into the same cache set and are accessed in order. The first 1, …, n lines will fill the cache ways, while the n + 1 access will evict the first memory line from the set, since all the set ways are full.
A potential issue arises with LRU policy when a program needs to access cyclically n + 1 memory lines (“program working set”) that are mapped to the same n way cache set. This is referenced as a ’set thrashing’ and will result in 0% hit rate. If we compare LRU policy to a random policy, depending on the workload, some studies have shown that LRU and random replacement policies have the same hit rate on average.
Recent studies have tried to predict intel’s CPU eviction policy for the LLC. The researchers suggest the following policy; Each cache set has an array in the same size of ways, that holds 3 bits per cell (a number between 0 to 3). When a new line is loaded into a L3 cache set, the suitable cell in the array is updated to the value 3. The array values are referred as the “age” of each line in the set. Each time a line in the cache is being accessed, the CPU searches for it in L1, if it doesn’t find it there it will search for it in L2, if both of them will result as miss, the CPU will search in L3. In case the line is found for the first time in L3 cache, it will decrease the age of this line by 1. When a new line (not in the cache) is accessed, and an eviction needs to be made, the CPU checks the age array (in the suitable cache set), and evicts the first line that it’s age is 3, if no line has the age 3, it evicts the first highest age that was found. Moreover, the researchers suggest that the processor has another policy, which enters the lines with the age of 2.
When implementing a cache side-channel attack, we will normally want to evict some special memory location from the cache. Considering a non-LRU replacement policy will mean that evicting a memory line from the cache will not necessarily be practical, since there is no guaranty that if the attacker accesses memory locations in a specific pattern we will evict the whole set from the cache.
Caches on Intel CPUs
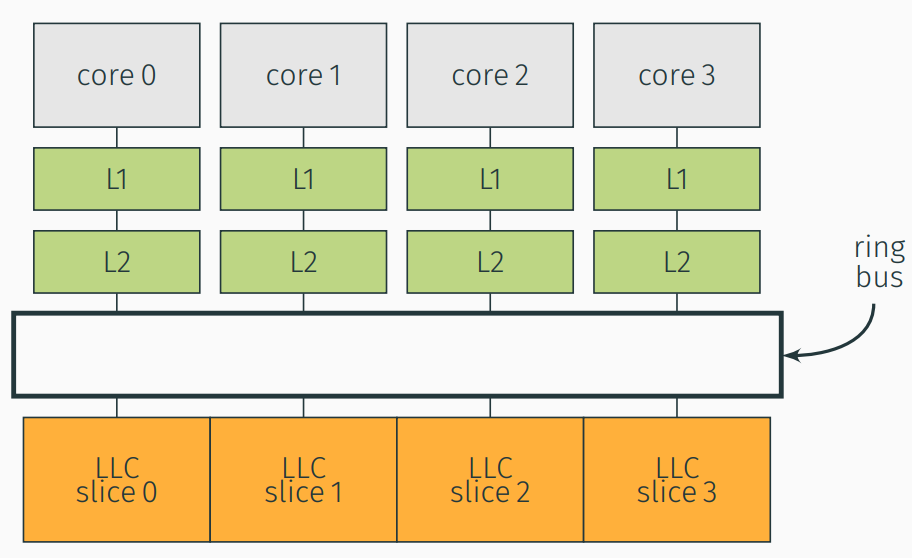
In we can see an abstraction of an Intel CPU architecture, on which every core has its own dedicated L1 instruction and data cache, in addition to a slightly bigger L2. All cores are connected via an interconnected bus to the last level cache (LLC/L3). The LLC is often sliced into the number of cores, having a dedicated slice to each core, while having all cores being able to access all slices. The common practice is that the different levels of caches are inclusive, meaning that a lower level cache is a super-set of the higher ones.
In order to preform a cache side-channel attack, an attacker can optimize its cache usage, among other things, using the following command: prefetch - A suggestion to the CPU that some memory line will be accessed soon, can trigger fetching that line into the cache by the CPU. clflush - Cache line flush, instructs the CPU to flush a memory line from all levels of the cache. The two instructions are based on virtual address.
The different latencies of the different cache levels, as well as the timing difference between a cache miss and a cache hit (as can be seen in ), are the main primitives of most cache side-channel attacks that will be discussed by the end of this chapter.
Cache Attacks Techniques
Microarchitectural attacks exploit hardware properties that allow inferring information on other processes running on the same system. In particular, cache attacks exploit the measurable timing difference between the CPU cache and the main memory. They have been the most studied microarchitectural attacks for the past 20 years, and were found to be powerful to derive cryptographic secrets . In such attacks, the attacker monitors which memory lines are accessed, not the content of a certain memory line.
Cache attacks are being used in one of the two following common scenarios:
-
Covert channel: two processes communicating with each other when they are not allowed to do so, e.g., across VMs.
-
Side channel attack: one malicious process spies on benign processes, e.g., steals crypto keys, spies on keystrokes etc.
We will focus on side-channel attacks.
Cache Side-Channel Timing Attacks
Every timing attack works by the following steps:
-
Learning timing of different corner cases.
-
Recognizing these corner cases by timing only.
Here, our corner cases are hits and misses.
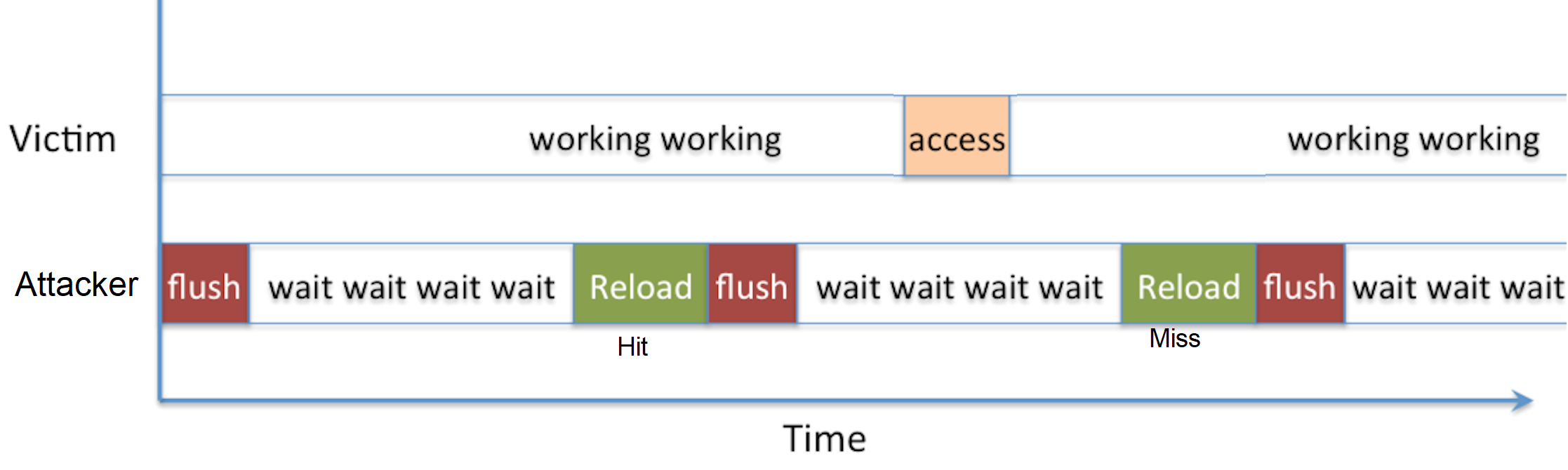
Building the Histogram
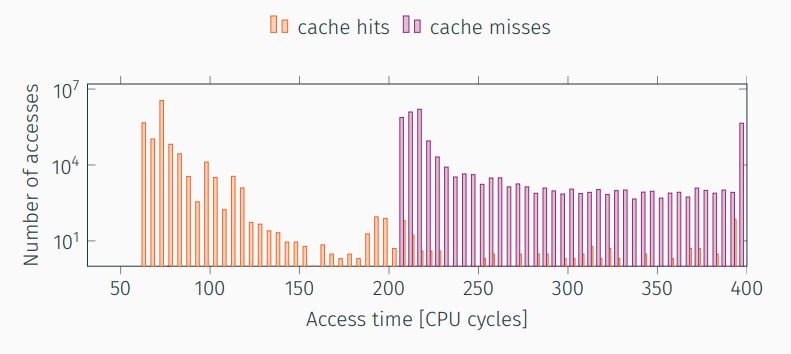
The first step towards the attack is to build the histogram of the corner cases, cache hits and cache misses. We measure the time for each case many times in order to get rid of noise. Thus, we have a histogram and we can find a threshold to distinguish the two cases.
Building the histogram for cache hits is done by the following loop:
-
Measure time.
-
Access variable (always cache hit).
-
Measure time again.
-
Update histogram with delta.
Building the histogram for cache misses is done by the following loop:
-
Flush variable (
clflushinstruction). -
Measure time.
-
Access variable (always cache miss).
-
Measure time again.
-
Update histogram with delta.
Having the two histograms, as in , we determine the threshold to be as high as possible such that there will be no cache misses below.
How to Measure Time Accurately
Consider the fact that the time intervals of our cases are (relatively) very short timings, we ask how to measure time accurately. For such short timings, it is common to use the Time Stamp Counter (TSC) via the unprivileged rdtsc instruction as following: […] → rstsc → function() → rstsc → […] By using this instruction, due to out-of-order execution, the actual execution order could be different, resulting with wrong measurements. The solution is to use the pseudo-serializing instruction rdtscp or to insert a serializing instruction like cpuid or use fence instructions like mfence .
We will now introduce two main cache attack techniques: Flush+Reload and Prime+Probe . Both of them are exploitable on x86 and ARM and can be used for both covert channels and side-channel attacks.
Flush+Reload
The attack is made of four basic steps and it goes as following:
-
Map. The attacker maps a shared library (Illustration in ), by doing that he will have a shared cache line with the victim.
-
Flush. The attacker flushes the shared cache line, it can be done via unprivileged instruction like
clflush. -
Victim. The attacker lets the victim load (or not load) the shared line, depending on the victim’s behaviour.
-
Reload. The attacker reloads the shared cache line. If the cache line has a hit the attacker infers that the victim loaded the data on the previous step, if the cache line has a miss the attacker infers that the victim did not load the data on the previous step.
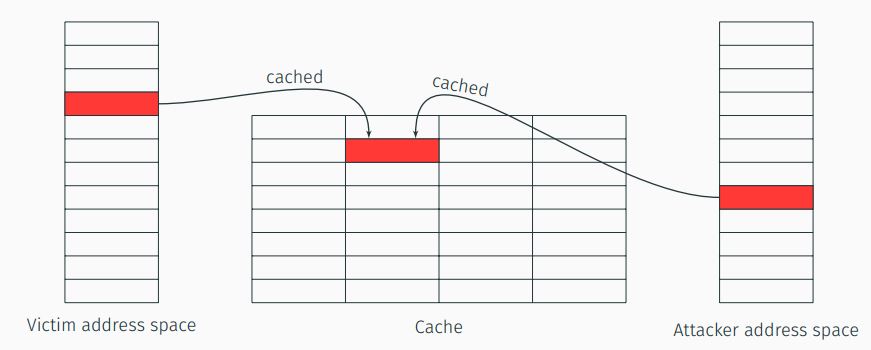
The first step (Mapping a shared library) can be done once, while steps 2-4 are repeatable as much as the attacker wants. The main advantage of this attack technique is the fine granularity, which is 1 memory line (usually 64B). On the other hand, this technique is somewhat restrictive, it needs clflush instruction, which is not always available e.g., on ARM-v7 and it needs a shared memory. Illustration of the attack flow in .
Shared Memory
A common method to achieve a shared memory is by a feature called page-deduplication. When two different independent processes are loading the same system library, some of their memory pages will be identical, when the operating system (in a cloud scenario - the hypervisor) identify separate identical physical memory pages, if page-deduplication is enabled, it will merge the physical pages in order to save physical memory, and two different virtual memory pages, one of each process, will be mapped into the same physical memory page. As of today, no serious cloud service company is using memory deduplication, e.g., Amazon EC2.
Evicts+Reload
demonstrated a substitution attack for Flush+Reload that does not require using a clflush instruction. This attack access physically congruent addresses in a large array, which is placed in large pages by the operating system. In order to compute physically congruent addresses, we need to determine the lowest 18 bits of the physical address to attack, which can then be used to evict specific cache sets.
Prime+Probe
First, for the Prime+Probe attack to work, the Last-Level-Cache (LLC) should be inclusive, i.e., the LLC is a superset of the L1 cache and the L2 cache. Thus, data evicted from the LLC is also evicted from L1 and L2. In inclusive caches, a core can evict lines in the private L1 of another core. The attack is made of the three following steps:
-
Prime. The attacker primes the cache by reading memory lines from its own exclusive memory (no shared memory).
-
Victim. The attacker lets the victim evict (or not evict) lines while running, depending on the victim’s behavior.
-
Probe. The attacker probes data in a similar way of the prime step but with the measurement of how much time it takes to load the lines (Hit / Miss), for each cache set, the attacker determines if the cache set has been accessed.
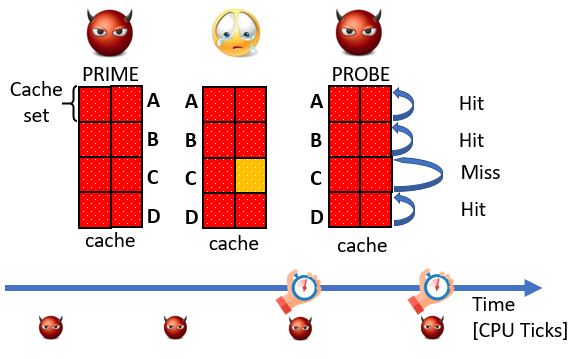
In comparison to Flush+Reload, this attack technique is less restrictive: it does not require clflush, does not assume shared memory and possible from JavaScript. On the other hand, the granularity is coarser: 1 set. Illustration of the attack flow in .
In practice, we need to evict caches lines without clflush or shared memory, so the following questions arise:
-
Which addresses do we access to have congruent cache lines?
-
How do we do that without any privilege?
-
In which order do we need to access them?
To achieve that, we need an eviction set: addresses in the same set, in the same slice and an eviction strategy.
Eviction Set
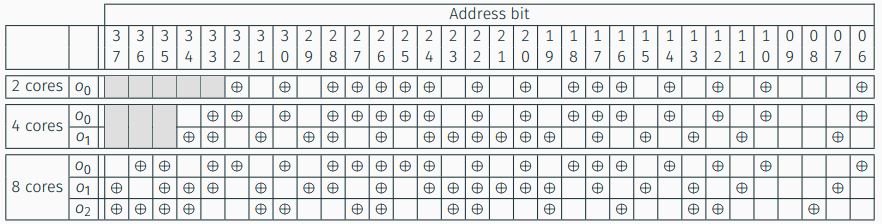
1 We want to target the L3 for cross-core attacks and we need addresses that have the same set index. Consider the following cache settings, L3 for a 2-core CPU: 4096 sets, 64B-lines, 12 or 16 ways. Since each memory address indicates one memory byte, the 6 least significant bits of the physical address indicates the line offset. For simplicity, we assume that the cache is not sliced, since there are 4096 = 212 cache sets, and the next 12 bits indicate the cache set. The L3 is physically indexed, so we need to choose addresses with fixed physical address bits. Unfortunately, address translation from virtual to physical is privileged. One of the virtual addresses’ properties is that a page offset stays the same from virtual to physical address. Thus, some of the least significant bits of the virtual address can be used as a sneak peek to the physical address. Typical page size is 4KB, which means just 12 bits of page offset, i.e., 6 bits of line offset and 6 least significant bits of the cache set out of 12. To overcome this limitation, we can use a special type of enlarged pages called Huge Pages, which are 2MB size each, that is - 21 bits of page offset. This way, the set index bits are included in the 21 LSB of the address.
We now have another issue; in practice, the L3 is divided into slices, as many slices as cores. We usually have 2048 sets per slice, that is, actually 11 bits for the set index. We cannot infer the slice number directly from the address, neither from the virtual or the physical. The slice number of each memory line is determined by a hash function, which takes all the address bits as input, including physical page number bits (outside the known bits from page offset). The Illustration below shows the address bit indication for both typical pages and huge pages.
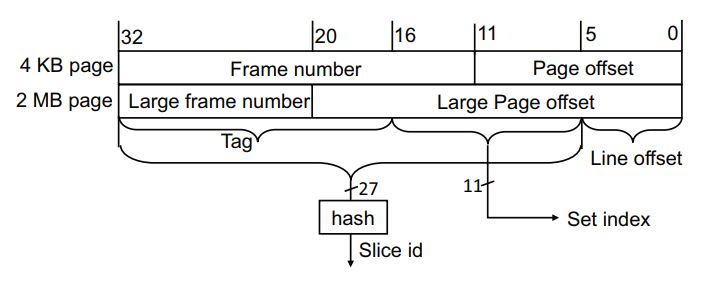
Also, the mentioned hash function is undocumented; it designed for performance. But, it does not mean that it is impossible to target the same set in the same slice. Previous work showed that the hash function could be reverse engineered, for example, in .
If the function is unknown, the process will be somewhat slower. But an eviction set can still be achieved via the following algorithm:
-
Construct S, set of addresses with the same set index.
-
Access reference address x ∈ S (to load it in cache).
-
Iteratively access all elements of S.
-
Measure t1, the time it takes to access x. it should be evicted.
-
Select a random address s from S and remove it.
-
Iteratively access all elements of S\s.
-
Measure t2, the time it takes to access x - is it evicted?
-
If not, s is part of the same set as x, place it back into S.
-
If it was evicted, s is not part of the same set as x, discard s.
-
Note that for a CPU with c cores: 16/c addresses in the same set and slice per 2MB page, we can apply the same algorithm with groups of addresses instead of single addresses and speed up the eviction set building process by up to three orders of magnitude.
Eviction Strategy
In the Prime or the Probe step, the attacker evicts a cache set by filling it with n addresses for a n-way cache. If the replacement policy is LRU, it access addresses from eviction set 1 by 1. If the replacement policy is not LRU, the eviction rate is lesser than 100%, e.g. 75% on Haswell. For non-LRU caches, we can use some heuristics, as in , that will result in a higher eviction rate.
Conclusion
To sum it up, in practice, for Prime+Probe on recent processors we need:
-
An eviction set, i.e., addresses in the same slice and with the same set index. Depends on the addressing.
-
An eviction strategy, i.e., the order with which we access the eviction set. Depends on the replacement policy
Hardware vs. implementations
To perform a cache side-channel attack on some software, you need two things: First, shared and vulnerable hardware. Note that there will be no side-channel if every memory access takes the same time or if you cannot share the hardware component. Second, a vulnerable implementation. Note that a vulnerable implementation does not mean that the algorithm is vulnerable. For example, we can take the specific implementation of AES and RSA, this does not imply that AES and RSA are defective. Not all implementations are created equal.
To sum up, hardware will most likely stay vulnerable, so patch implementations when you can. And remember, constant time is not enough - because an attacker can modify the internal state of the micro-architecture.
Step by Step Attack Demo
The target of the attack in this demonstration is to get the timestamp of the keystrokes pressed by a user in a gedit program. We only target the timestamps and not the keystrokes themselves, as we cannot fully recover the pressed keys.
The demonstration is performed on a non-virtualized Linux environment. A requirement to perform the attack is having an Intel CPU, as we need the inclusive property of the L3 cache. The code for performing the attack can be cloned from the git repository . It is based on the Flush+Reload cache attack that we mentioned in 1.2.2 presented in and .
The attack is performed in 3 steps: calibration, profiling and exploit. For each of these steps, a folder exists in the repository.
Step 1: Calibration
In this step, we want to create the histogram, which depicts the cache misses and hits as a function of the number of CPU cycles. Then we will be able to extract the threshold that will match the CPU on which we perform the attack. In order to perform the calibration, we run the following commands:
$ cd calibration
$ make
$ ./calibration
The calibration works by generating multiple cache misses and cache hits and measuring the number of CPU cycles it takes to access a variable. Each of these cases is being performed multiple times in order to get rid of the noise.
We build a histogram of cache hits and cache misses as described in previous 1.2.1.1. The output of the calibration program is a histogram of the cache misses and hits as shown in .
We can then find the threshold so it satisfies the following requirements:
-
As high as possible
-
Most cache hits are below it
-
No cache miss below (we may see one exception due to the way the calibration is coded)
For example, in , we can see that there is a clear line in approximately 220 CPU cycles.
Step 2: Profiling
After finding the threshold, we can now profile in order to find the cache lines that are useful to get information about the target program. Choosing gedit as the target program, we first need to find the shared library that it uses so that we can give it as an input to the profiler. We then need to find this shared library file location and size. In order to do that, we can use the following one-liner:
$ cat /proc/`ps -A | grep gedit | grep -oE "^[0-9]+"`/maps | grep r-x | grep libgedit
This is equivalent to first finding the pid with
$ ps -A | grep gedit
and then using this pid in
$ cat /proc/<pid>/maps | grep libgedit
then copying the line with r-xp permissions (x stands for executable).
Doing that gives the following line (memory range, access rights, offset, –, –, file name):
7f2d83197000-7f2d8326d000 r-xp 00000000 08:02 1080575 /usr/lib/gedit/libgedit.so
We need to update the threshold to the value we found in the calibration step before we can feed the above line to the profiler. We can do this by editing the profiler source file (under the profiling directory) and updating the line with the constant
#define MIN_CACHE_MISS_CYCLES
to the threshold we have.
After updating the threshold, we can run make to compile the profiler. We then use sleep 3 so we can have time to trigger the event before the profiler starts, and run the profiler with the line we found above:
sleep 3; ./profiling 200 7f2d83197000-7f2d8326d000 r-xp 00000000 08:02 1080575 /usr/lib/gedit/libgedit.so
The profiler does its job by loading the shared library to its address space, and then doing flushes and reloads for each address in the address range given by the offset argument (0 in the above case), and the library size (1080575 bytes) for some given time (200 μsec for every address in the above command). The output is the number of hits that happened in every address.
The idea is that if a 0 is shown for a given address while triggering the event, then it means that the line in this address was never accessed for this event. Eventually, we will get lines with some cache hits, and we want the ones that have at least a non zero value when profiling.
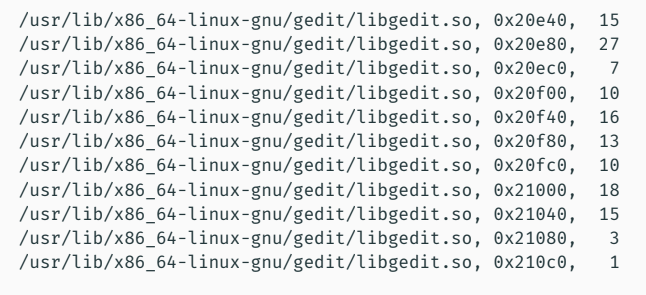
Running the profiler with offset 0 while jamming a key, doesn’t seem to generate cache hits, and we may only see 0. The reason for that, is that the code that handles keystrokes in the library is probably just not in the beginning of the library. Instead (and this is a cheat), we change the starting offset to 20000, and this is approximately where the code that handles keystrokes in the library is found. In real life we will have to wait until we get to something by running the template attack on the whole library. Running the profiler with this new offset, we can see in some addresses that have a non-zero value quite fast. The addresses with the high numbers are the ones we should further investigate in the exploit phase.
Step 3: Exploitation
Equipped with the addresses from the previous step, we can now go to the exploitation dir, change the threshold constant (MIN_CACHE_MISS_CYCLES) as we did for the profiler, and run make. Then we can run the program by
./spy <library-file> <offset>
giving one of the addresses we found as the offset argument. Starting from the address with the most hits, we can see that even if we are not pressing any key, we are still getting events. The reason for that is that this address is related to the blinking cursor. This is, of course, not really interesting information, and we can understand that it is not always the address that has the most hits that is the most valuable. Trying the next interesting address indeed gives us information about the pressed keys, which is what we wanted to achieve. However, moving the mouse also gives us a lot of hits, which is not perfect. We will need to inspect the addresses one by one until we find an address that will only work for keystrokes.
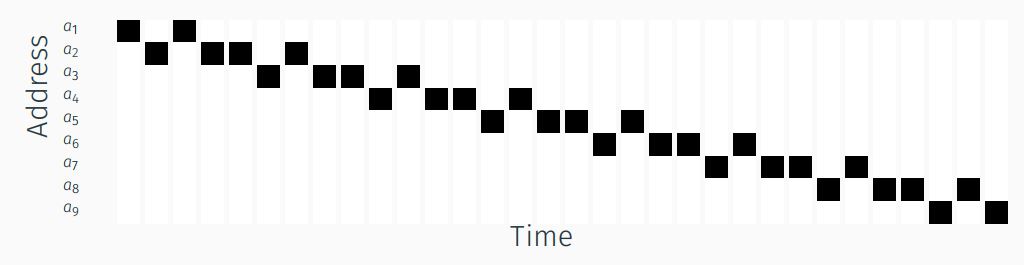
We can even further improve the attack by finding the complete matrix of the keystrokes for each of the keys as shown in . We can see that for different keys, there is a different “signature” of the accessed addresses. Although we may not be able to precisely identify each keystroke, we can try to group the keystrokes to different addresses and eliminate some guesses if we can spy on more than one address at a time.

Finally, as it may be annoying to perform the above process manually, we can automate the event triggering and other stuff as shown in .
Cache Template Attacks Paper
-
Cache Template Attacks Paper - The article is called “Cache Template Attacks: Automating Attacks on Inclusive Last-Level Caches” by Daniel Gruss et el. Cache Template Attacks consist of two phases. In the profiling phase, they determine dependencies between the processing of secret information and specific cache accesses. In the exploitation phase, they derive the secret values based on observed cache accesses. Among the presented attacks is the application of Cache Template Attacks to infer keystrokes and—even more severe—the identification of specific keys on Linux and Windows user interfaces. Furthermore, they perform an automated attack on the Ttable-based AES implementation of OpenSSL that is as efficient as state-of-the-art manual cache attacks.
Cache size test
In order to test the cache size we use a random cyclic permutation access pattern, where each cache line (64 bytes) in an array is accessed exactly once in a random order before the sequence repeats. Each access is data-dependent so this measures the full access latency (not bandwidth) of the cache. The cache size test can run on google colab or on private computer, in case the test will run on google colab the test will measure google server cache size. first, we check the value of the TSC then we perforn The function that execute in loop dereferencing dpointer-address and jumping to the value the value is random address (index) of the data buffer
Pseudo code of the assembly:
p = dpointer_address
for (int i=ITS;i;i--)
{
p = *(void**)p;
p = *(void**)p;
...
ASM_BLOCK_SIZE
...
p = *(void**)p;
}
and then we check for the TSC once again and saving the average time.
Micro architecture buffers sizes testing tool
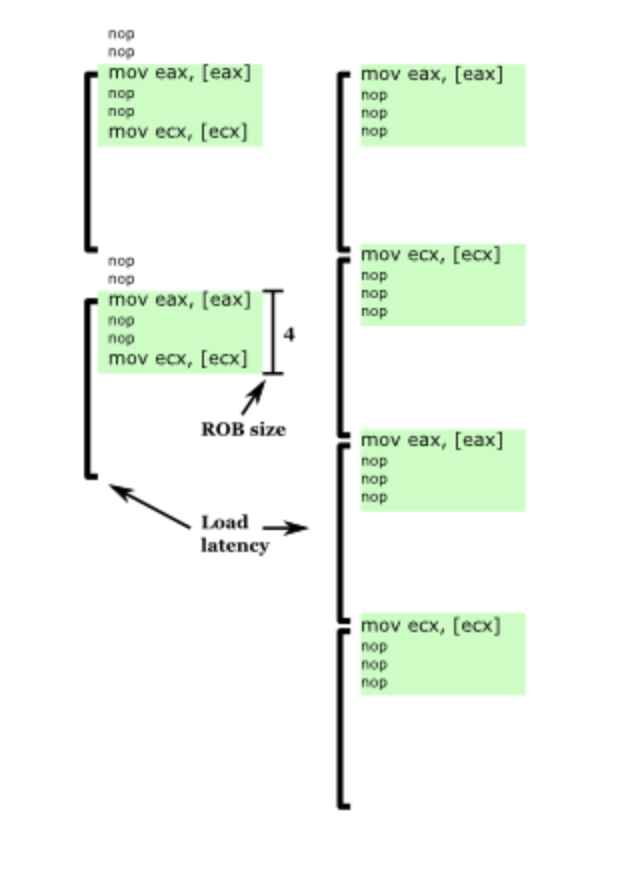
The instruction window constrains how many instructions ahead of the most recent unfinished instruction a processor can look at to find instructions to execute in parallel. In this tests we use a suitable long-latency instruction to block instruction commit, it is able to observe using CPU cycles measurements how many instructions ahead the processor is able to execute once the instruction commit is stalled. Between two long-latency instructions we put a dynamic number of filter opcode that allow us to measurement different micro architecture component size.
Filter number 0
On microarchitectures that rename registers using a physical register file (PRF), there are often fewer registers than reorder buffer entries (because some instructions don’t produce a register result, such as branches). If the filler instruction is produces a register result (ADD), we can measure the size of the speculative portion of the PRF. This uses a series of general-purpose register for ADD operation, each one of which should consume a physical register, to test the size of the speculative register file.
Filter number 2 and 3
Repeating the test with MOV or CMP filter instructions can show whether register to register moves are executed by manipulating pointers in the register renamer rather than copying or comparing values. This uses a series of general-purpose register for MOV operation, each one of which should consume a physical register, to test the size of the manipulating pointers rename optimization.
Filter number 1 and 4
These tests use single byte or double byte NOPs to detect the Re-ordering buffer (ROB) size. They should both give the same answer, since only difference is that single byte NOPs tend to disable the use of micro-op cache since they are too dense, while double-byte NOPs use the cache. I wouldn’t expect that to affect the apparent ROB size, but it’s nice to be able to check!
Filter number 32 and 33
These determine the load buffer size (test 32) and store buffer size (test 33) respectively, by using loads and stores as the filler instructions. This is a python testing tool for micro architecture buffers sizes like ROB size described by Henry Wong on his blog inspired by robsize github repository.
-
From now on, most of the details are correct for a common Intel CPU architecture. ↩