Fault Attacks
- Fault Attacks
View the video recordings for this chapter
Introduction to Fault Attacks
Up until now in the course we learned about passive attacks – i.e. attacks which measure leakage such as timing information and power traces. The advantage of these attacks is that they allow an attacker to acquire information in the process of an ongoing computation e.g. an AES key before it was fully mixed with the input – this fact can help the attacker extract secrets.
In fault attacks we will become active in the sense that we will give the device-under-test (DUT) additional inputs such as heat or radiation.
One problem with Fault attacks is that they use the strongest attack model, meaning – we assume most power on the attacker’s part.
Active Attacks
Definition:
“A fault attack is an active attack that allows extraction of secret information from cryptographic devices by breaking those devices.”
In fault attacks we, the attackers, are active – we give additional inputs beside the main input such as:
-
Fuzzing (garbage or bad input)
-
Radiation
-
Heat
-
Vibration
-
Power spikes etc.
This way, we receive other (usually erroneous) outputs which might give us additional information about the computation and/or the secret. This process is described in .
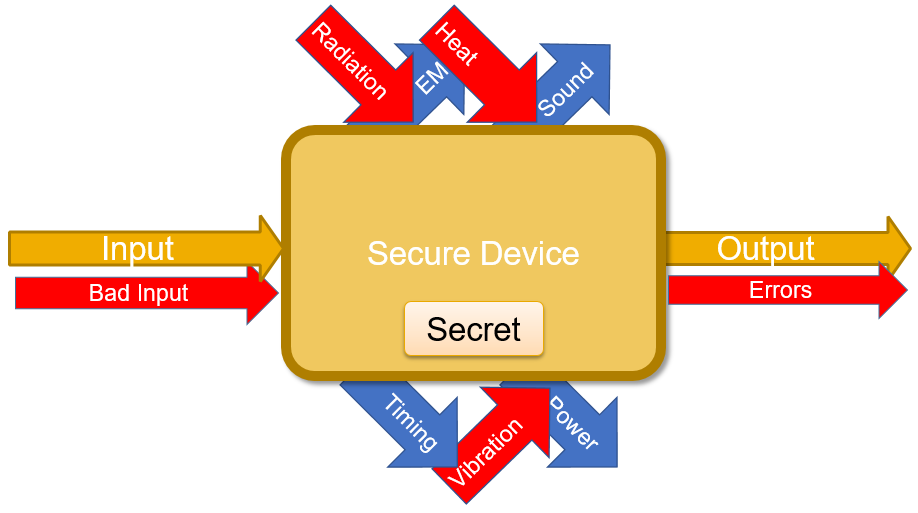
Like with passive attacks, some of these outputs can be acquired at different stages of the computation process.
Many fault attacks are inspired by studies in the field of reliability: a study in reliability will research a device’s physical boundaries e.g. the maximum or minimum temperature under which it performs reliably. Other examples of reliability studies are aimed at improving device performance under extreme conditions such as:
-
Space and X-Rays
-
Dense CPU Layouts
-
Data Center Recovery (ECC-RAM)
A security researcher implementing fault attacks will, on the other hand, purposefully subject the DUT to extreme conditions in order to inject errors in the device’s functionality to achieve their goal. In that sense, a reliability study of a given device can lay the ground-work for the fault attacks to come.
“In the reliability community things happen by mistake. In the security community – things happen on purpose.”
Breaking a device-under-test
How can breaking a device help an attacker?
-
BORE – “Break Once, Run Everywhere”: Some device families share a single secret among all instances.
-
Repairable Devices: Temporary breakage is fine. Sometimes restarting the device is enough to “repair” the damage.
-
Partial breakage: Sometimes it’s convenient to break part of a device, for example – destroy the subsystem responsible for DRM verification.
Fault Attack Taxonomy
The three ways we can examine a Fault Attack in order to understand it are:
-
Method - “How to inject the fault?”
-
Properties - “What class of fault to create?”
-
Target - “Which part of the system to break?”
Fault Methods
Power Supply Attacks
What happens if the device is underpowered? As we have previously seen, power in electronic devices is used to drive the CMOS transistors. If the device is slightly underpowered it might fail to switch some of the transistors and thus produce false calculations, and with even less power it might struggle with getting into operational state (boot loop) or even transition to an entirely faulty state. Another attack method involving the power supply is injecting power spikes (to a similar effect).
Some parts of a device are typically more sensitive to the power supply than others, and thus under-powering or over-powering the device will de-stabilize it and inject faults.
The obvious scenario for such an attack is when the DUT belongs to or is being controlled by the attacker – for example if they’re examining their own set-top box etc. In that case, the attacker can supply the device with as much/little power as they wish.
Another example of such attack scenarios is in the field of RFID readers – the device powering an RFID chip is the reader, so a malicious RFID reader can over/under-power the chip to achieve various faulty results. For instance, if the RNG is connected to the power supply, we can mike its generated numbers deterministic.
Clock/Timing Attacks
The clock is typically a bus shared by many of the system’s components which synchronizes the propagation of calculations through the system – i.e. at the beginning all inputs are ready, and when there is a rising edge on the clock bus they start propagating throughout the various computational components. When all computations are finished they all wait for the next rising edge on the clock bus in order to proceed to the next stage. In a clock glitching attack the attacker would inject a rising edge on the clock bus at an arbitrary time. This way only some of the computations will have finished by that time while others are still being processed, and thus the device will be in a faulty (unstable) state.
A notable example is the attack on Mifare Classic RFID chips we talked about in the beginning of the course – the RNG in the chip is dependent only on the time between powering up the RFID tag and challenging it. An RFID reader operated by the attacker can control both parameters, thus making the generated challenges deterministic.
Temperature attacks
This attack method relies on the physical property of electrons (current). Electrons “jump”, and the higher the temperature – they will jump more frequently and to longer distances. If a device gets too hot – enough electrons can “jump” over the insulation layer in a transistor, for instance, to flip it from logical 1 to 0. This results in a fault.
Because of the ubiquity of devices failures due to temperature, nowadays temperature sensors are integrated into most devices, so when it overheats – the device will shut down.
An attacker can bypass the temperature sensor by disconnecting it. Another method would be to quickly alternate the temperature of the device from extremely high to extremely low, so that on average the temperature is reasonable, but it will still experience faults during the extreme phases of the cycles.
In an interesting research paper a type-confusion attack on the Java virtual-machine was demonstrated: at first, the entire memory was filled with small arrays (say of size one). The Java VM is type-safe, so it is normally impossible to access one of the memory regions using a pointer to a different region. To inject a type-confusion fault the researchers used a 50W light bulb to heat the memory chip of the device enough to flip some of the bits (for illustration see ). As a result, a small portion of the data-structures describing the arrays in memory now held wrong values (e.g. changed their value from size* = 1 to *size = 20). At this point, some affected data-structures contain a header of a different data-structure, to which the attackers now have read and write access. Changing the header of the second data structure to an arbitrary value gave the attackers access to the entirety of the device’s memory.

Optical, Electromagnetic
When a laser hits a transistor it changes the energy level of the silicon inside, and sometimes it can change the transistor’s state. Notably different wavelengths are absorbed by different materials, so in a typical silicon chip different lasers will hit different layers of the device etc. Magnetic/Electromagnetic radiation and pulses have similar effects.
The underlying principal of those attacks is that the attacker forcefully injects charge (energy) into the device. Once it’s stored inside it will have to dissipate one way or another, so as a result it injects a random faulty state into the device.
Reading from RAM
All of the attacks described above require very high engagement with the DUT – in order for the attacker to control the power/clock sources, for example, they sometimes would need to drill, cut or otherwise tamper with the device. Shining a laser on a device requires at the very least having it at a visible distance.
The final attack method involves only reading from memory, and thus is very practical and requires very little physical engagement. This attack method is called Rowhammer and is discussed later in the lecture.
Fault Properties
In this section we discuss:
-
How controllable is the fault’s location/size? Precise? Loose? None?
-
How controllable is the fault timing?
-
What’s the fault’s duration? Transient? Permanent? Destructive?
Destructive fault attacks on cryptographic devices
What can be done with fault attacks to symmetric ciphers?
Easy example:
Imagine that we have a pile of cipher devices with a 64bit key length, which work the following way: we can give the device a key and it tells us whether it’s the right key.
What if we have a destructive fault attack that resets the top 32 bits of a device’s key? We can brute force the key in 2 ⋅ 231 instead of 263 (on average):
First we inject the fault into one of the devices and brute-force the lower 32 bits of the key (O(231)), then we pick another device from the pile and brute-force only the higher 32 bits (another O(231)).
A less trivial example:
We have a public-key device which we can ZAP and one bit of the key flips to zero.
We can save all of the plaintexts-cipher pairs until we reach the one matching an all zero key – which we can pre-calculate. This gives us the Hamming weight of the key. Now we go back one plaintext-cipher pair – we know that pair’s key’s Hamming Weight to be exactly one – meaning we need to brute-force only N keys (N is the key bit-length). Now we have the position of a single bit of the key.
If we iterate all the way backwards to the original plaintext-cipher pair, we can acquire the key in O(N2) time!
Fault Target
What could be targeted by a fault attack?
-
Input parameters (fuzzing, power and clock glitching)
-
Storage (volatile/non-volatile)
-
HDD – Destructive (persists after reset)
-
RAM – Permanent
-
Cache – Transient
-
-
Data processing: injecting a fault mid-computation and the device gives a different answer.
-
Instruction Processing/Control Flow: inject a fault in the IP register and change the instruction flow. There are various examples that demonstrate the usefulness of this type of target
-
change the program counter to compromise control flow
-
ARM32 instructions are very densely packed, thus there is a very high probability of hitting a valid instruction after flipping a single bit. For example,
jnzandjmpare only one bit apart. -
Change for loop condition in programs such as one that reads from a buffer, if the loop is infinite, it would dump RAM contents including source code.
-
Two examples of Fault Attacks targeting Control Flow:
-
The CHDK hacking community, used to dump the firmware of Canon cameras via blinking one of their LEDs .
-
The “Unlooper”: Back in the 90’s pay-tv devices started cryptographically signing the content, and if the cryptographic checksum did not check out – the device would enter an endless loop. The hacking community invented “unloopers” – a gadget that would inject a power spike and fault the IP register, so that the pay-tv device would jump to some other section of the code, from which point it would function normally.
Fault attack on RSA-CRT
RSA decryption
n = p ⋅ q, M ≡ Cd ≡ Me**d (mod ϕ(n)) ≡ M1 ≡ M (mod n)
RSA decryption is hard!
Let’s speed it up using CRT (the Chinese Remainder Theorem): Multiplication operations are O(|n|2). If we can do operations (mod p) and then (mod q) instead of (mod n), we will reduce computation time by half.
Explanation:
The bit-lengths of p and q are each half that of n \(\|p\|=\|q\|=\\frac{1}{2}\|n\|\) The computational complexity of multiplying by a number of length x is (roughly) O(x2). Thus: \(O(\|p\|^2) = O(\|q\|^2) = \\frac{1}{4}O(\|n\|^2) \\Rightarrow (O(\|p\|^2) + O(\|q\|^2)) = \\frac{1}{2}O(\|n\|^2)\)
So if we could multiply by p and q instead of by n, we would cut each multiplication operation’s time complexity in half!
Chinese Remainder Theorem
The idea is that if we know both x (mod p) and x (mod q) then we can easily calculate x (mod n).
So, given a message M, calculate Mp and Mq: Mp ≡ Cd (mod n) ≡ Cd (mod p), Mq ≡ Cd (mod n) ≡ Cd (mod q)
To combine the values, we do: M* = CRT(Mp,Mq)= Mp ⋅ q ⋅ (q−1 (mod p)) + Mq ⋅ p ⋅ (p−1 (mod q))
It is easily provable that M* (mod p) = Mq and M* (mod q) = Mp, so by the Chinese Remainder Theorem, this value must be equal to M.
The Boneh, DeMillo & Lipton Fault Attack on RSA-CRT
The attacker has a decryption box (known plaintext scenario) with public key n and would like to recover d (the private key). Additionally, the attacker knows that the decryption box is decrypting using CRT. Finally, let us assume that the attacker can inject a fault (any fault) in the decryption process.
The attacker first gets M = Mp ⋅ q ⋅ (q−1 (mod p)) + Mq ⋅ p ⋅ (p−1 (mod q)) through the regular decryption process.
Then, the attacker primes the device to re-calculate the message from the same cipher, this time injecting a transient fault during the calculation of Mp, resulting in the device erroneously producing M′p instead: M′p ≠ Cd (mod p) The device will then proceed to combine M′p with the correct result of Mq, resulting in: M′ = M′p ⋅ q ⋅ (q−1 (mod p)) + Mq ⋅ p ⋅ (p−1 (mod q))
Now the attacker can calculate the value of M − M′: [Mp⋅q⋅(q−1 (mod p))+Mq⋅p⋅(p−1 (mod q))]− [M′p⋅q⋅(q−1 (mod p))+Mq⋅p⋅(p−1 (mod q))]= (Mp−M′p) ⋅ q ⋅ (q−1 (mod p))
Finally, calculating the gcd of n and M − M′ yields: gcd (n,M−M′) = gcd (p⋅q,(Mp−M′p)⋅q⋅(q−1 (mod p))) = q
Why does this work?
The greatest common divisor of n and anything can be only p, q, n or 1. On the other hand, Mp and M′p can never be multiples of p, otherwise both would equal 0. So, by that reasoning, gcd (p⋅q,(Mp−M′p)⋅q⋅(q−1 (mod p))) must equal q, and thus we have cracked the cipher using a single fault attack.
A later paper co-written by Arjen Lenstra further improved upon this attack to not require knowledge of M.
BML in practice:
A paper showed how ZAPPING a device with an electric spark from a lighter during computation can achieve the described effect.
Rowhammer
In the final section, we will describe the Rowhammer attack.
Rowhammer attack taxonomy
-
Target: DRAM on modern computers
-
Properties: Permanent, controlled location
-
Method: Memory accesses
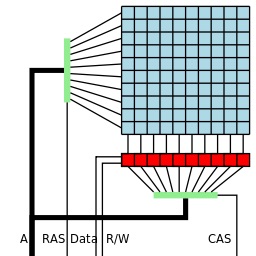
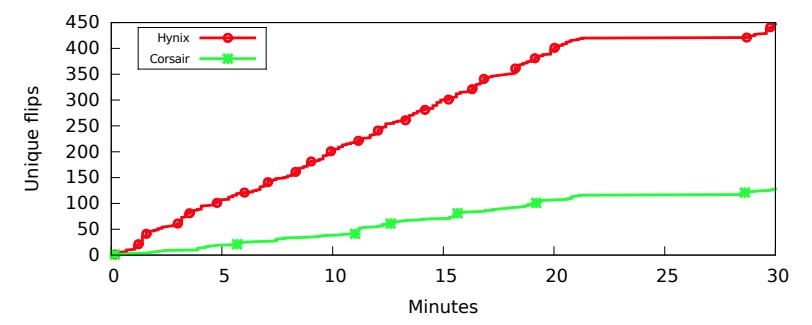
Double-sided Rowhammer
DRAM is the most common type of volatile memory. It is slow, dense and cheap relatively to SRAM. Every bit of RAM is stored in a single capacitor. Capacitors lose charge and they need to be periodically refreshed. The bits are selected using the row buffer.
The attack utilizes the physical structure of RAM chips in order to induce faults: Due to parasitic leakage in DRAM capacitors, if enough consecutive reads are performed on the immediately adjacent rows eventually a bit will flip in the target row.
The fault attack exploit code is as follows:
while (true) {
x = memory[address1];
y = memory[address2];
}
What happens here?
We infinitely read from adjacent rows, so eventually, we can cause a bit confusion.
Challenges
The challenge of CPU caching
The CPU cache prevents the same memory address to be read consecutively from main memory, for performance reasons. To circumvent this limitation, several techniques can be employed:
-
Intel CPUs provide non-temporal read/write opcodes – special instructions that read from memory and don’t get cached.
-
The special
clflushinstruction can be used to explicitly flush the cache after each read operation (privileged operation). -
Finally, cache-population algorithms had been extensively studied and reverse-engineered, so it is possible to arrange for arbitrary cache misses.
Address findings:
The attacker needs to find addresses that are on the same chip, and are in adjacent rows for the attack to work.
Countermeasures
Refresh-rate increase:
In order to overcome parasitic leakage, DRAM chips already have a mechanism in place to read and then re-write the values stored in each row periodically. One method of overcoming Rowhammer could be to significantly increase the refresh-rate of the chip. This obviously results in both performance degradation and increased power consumption.
ECC-RAM:
High-end DRAM chips (typically meant for data center environments) contain error-correction coding (ECC) logic which can typically correct one erroneous bit and detect two (at which point it will crash the program/system). Those chips are immune to the basic form of Rowhammer described above, but as discussed later, are not bullet-proof.
Rowhammer variations
Flip Feng-Shui
Page de-duplication:
On modern systems, typically much memory is shared among many processes running on the system. This is even more true of virtualized environments where the guest and the host, for example, could run the same OS. A common optimization is for the system to detect and de-duplicate pages containing the same data, thus freeing up memory.
Rowhammer + page de-duplication:
In a paper researchers from VUA demonstrated how they can utilize page-deduplication in a virtualized environment to weaken cryptographic keys, resulting in unauthorized access via OpenSSH, and breach of trust via forging GPG signatures. The attack relies on the fact that the the attacker can read a de-duplicated page as much as they want. The attacker has to wait (or arrange) for a page containing sensitive information to be de-duped, then hammer on it until a bit in the key flips, making it much easier to factor.
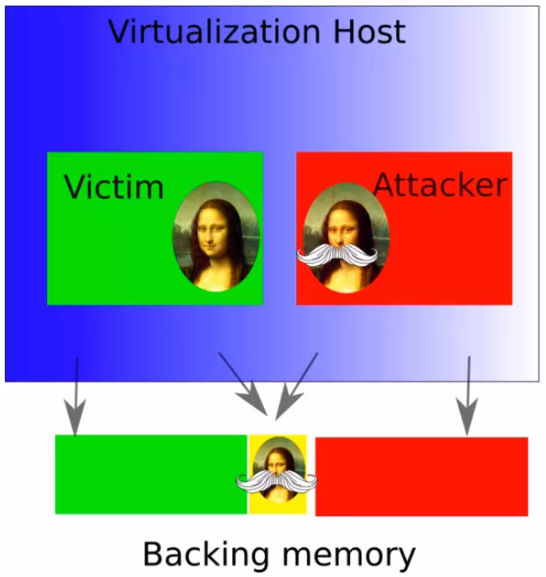
ECCPloit
In another paper researchers from VUA showed how they can use Rowhammer to quickly flip enough (typically three) bits on an ECC-RAM chip that error correction will not be able to detect it, thus defeating the ECC mitigation. The attack relies on the fact that error-correction takes time to compute, and this gives the attacker a window of opportunity.
Rowhammer-based attacks
RAMBleed
We will describe here Rowhammer based attack called RAMbleed which was presented in . While Rowhammer breaks data integrity, RAMBleed breaks also data confidentiality by allow the attacker read unauthorized memory areas. RAMBleed attack was implements against OpenSSH server allowing the attacker read RSA secret private keys.
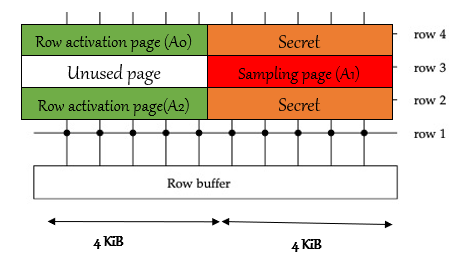
In order to perform this attack, the attacker need to get to specific memory layout, as describe in . The attacker own A0, A1 and A2 block. Then attacker force OpenSSH server to put its private RSA key in oranges blocks by exploiting linux buddy allocator which works in deterministic way. Then the attacker repeatedly accessing A0 and A2 blocks - this will access orange blocks as well because when DRAM access a part of the row, it access the whole row as well. This will hammer the red block and cause bit flips over there. The attacker can then read the red block- because he own it, and gets the RSA secret key.
The performance from this paper shows accuracy of 82% when reading OpenSSH host key. Reading the victim’s secret in 0.31 bits/seconds.
Suggested mitigations may be memory encryption, flushing keys from memory, probabilistic memory allocator and Hardware mitigations such as targeted row refresh and increasing refresh intervals.
Throwhammer - Rowhammer Attack over the Internet
There are some sophisticated Rowhammer exploits which allow an attacker, that can execute code on a vulnerable system, to escalate privileges and compromise browsers, clouds, and mobile systems. In all these attacks, the common assumption is that attackers first need to obtain code execution on the victim machine to be able to exploit Rowhammer, either by having (unprivileged) code execution on the victim machine or by luring the victim to a website that employs a malicious JavaScript application.
In Contrary to those attacks, In the ThrowHammer attack, the attacker can trigger and exploit Rowhammer bit flips directly from a remote machine by only sending network packets.
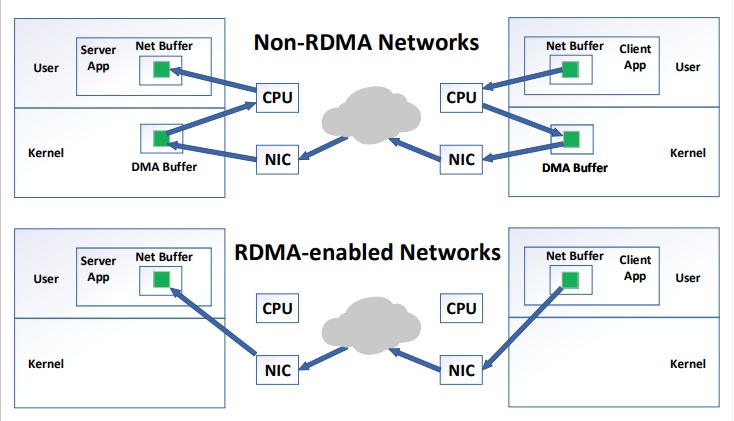
While it is true that millions of DRAM accesses per second is harder to accomplish from across the network than from code executing locally, today’s networks are becoming very fast. To achieve high-performance networking, some systems entirely remove the interruptions and expensive privilege switching, and instead deliver network packets directly to the applications. This approach might create large load on the cpu, so to reduce that load, some networking equipment include the possibility for Remote Direct Memory Access (RDMA). With RDMA, there is no need to involve the CPU on both client and server for packet transfer. The server and client applications both configure DMA buffers to the NIC (Network interface controller) through interfaces that are provided by the operating system. When the client application wants to send a packet to a server application, it directly writes it to its buffer as shown in .
In the ThrowHammer attack, the attacker is assumed to be able to generate and send legitimate traffic through a high-speed network to a target server (A common example is a client that sends requests to a cloud or data center machine that runs a server application), and that the target machine is vulnerable to Rowhammer bit flips. The end goal of the attacker is to bypass RDMA’s security model by modifying bits outside of memory areas that are registered for DMA in order to compromise the system.
The attack is executed by repeatedly asking the server’s NIC to send the client packets with data from various offsets within the shared buffer used by the RDMA protocol. This allows the attacker to perform double-sided Rowhammer similar to Flip Feng Shui .
An overview of the chapter can be found in the following link:
Related Work
Additional related work on the topic of fault attacks includes:
-
DVFS - Dynamic Voltage and Frequency Scaling attacks make use of voltage and frequency combinations which are considered unstable.
-
CLKScrew - a paper by Tang et al. that describes a technique that takes advantage of security vulnerabilities caused by the constant strive to improve energy efficiency, more specifically energy management mechanisms used in state-of-the-art mobile SoCs. The attack is based on overclocking CPU frequency to inject faults into the victim process and breach the isolated Trusted Execution Environment (TEE).
-
VoltJockey - a paper by Qiu et al. that describes a hardware fault-based attack on the TrustZone - a TEE security approach deployed in ARM processors. This attack, as opposed to the frequency manipulation in CLKscrew, uses software-controlled voltage manipulation. It is demonstrated on an ARM-based multi-core processor and manages to achieve several malicious goals: (1) acquire an AES key by cryptanalysis, (2) induce misbehavior in RSA decryption method to fake signatures and load unauthorized applications into TrustZone. More on VoltJockey in the next section.
-
Plundervolt - a paper by Murdock et al. , the first one that describes the use of voltage scaling for corruption of integrity and confidentiality of computations inside Intel SGX enclaves. The authors demonstrate full key recovery PoC attacks against RSA-CRT and AES-NI.
-
-
Speculative Fault Attacks - Such attacks make use of the behavior of modern processors and their attempt to predict and speculate the next instructions to be executed for maximum performance. CPUs will try to execute instructions ahead of time.
- Spectre - Exploiting Speculative Execution - a paper by Kocher et al that describes a speculative fault attack that involves inducing a victim to speculatively perform operations that would not occur during correct program execution and which leak the victim’s confidential information via a side-channel to the adversary.
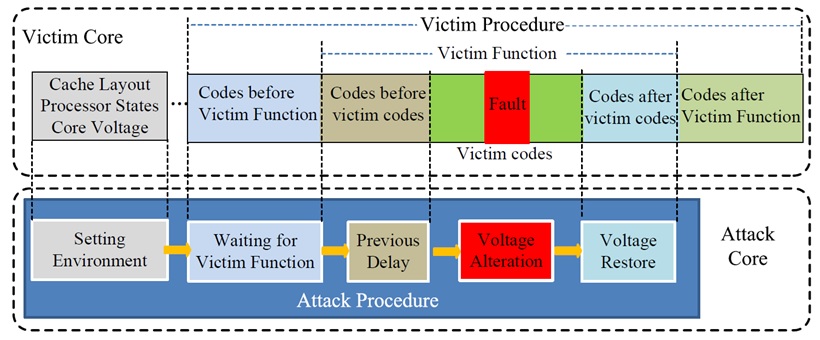
VoltJockey
As mentioned above, VoltJockey is a fault-injection attack, targeting the TrustZone execution environment of ARM processors. VoltJockey was deployed on the Krait multi-core processor, whose frequencies for each core can be different. However, the processor voltage is controlled with a shared hardware regulator, which introduces the main vulnerability that is exploited in this attack. VoltJockey uses software-controlled core frequency manipulation that is based on the susceptibility of DVFS. The attack was demonstrated in two use-cases that breach the system-wide secure technology in billions of ARM-based devices - TrustZone; (1) obtaining AES key, and (2) forge RSA signatures of unauthorized and possibly malicious applications. VoltJockey proved to be successful in a commercial device, the Google Nexus 6, and has demonstrated its dangerous implications in the secure execution environment TrustZone.
An illustration of the VoltJockey attack process can be found in Figure 1.9.